
Introducing, Critica
QA for AI Agents
Critica is an all-in-one AI testing platform that centralizes simulations,
observability, failure analysis, reasoning traces, and everything in between.


Introducing, Critica
QA for AI Agents
Critica is an all-in-one AI testing platform that centralizes simulations,
observability, failure analysis, reasoning traces, and everything in between.
Introducing, Critica
QA for AI Agents
Critica is an all-in-one AI testing platform that centralizes simulations,
observability, failure analysis, reasoning traces, and everything in between.
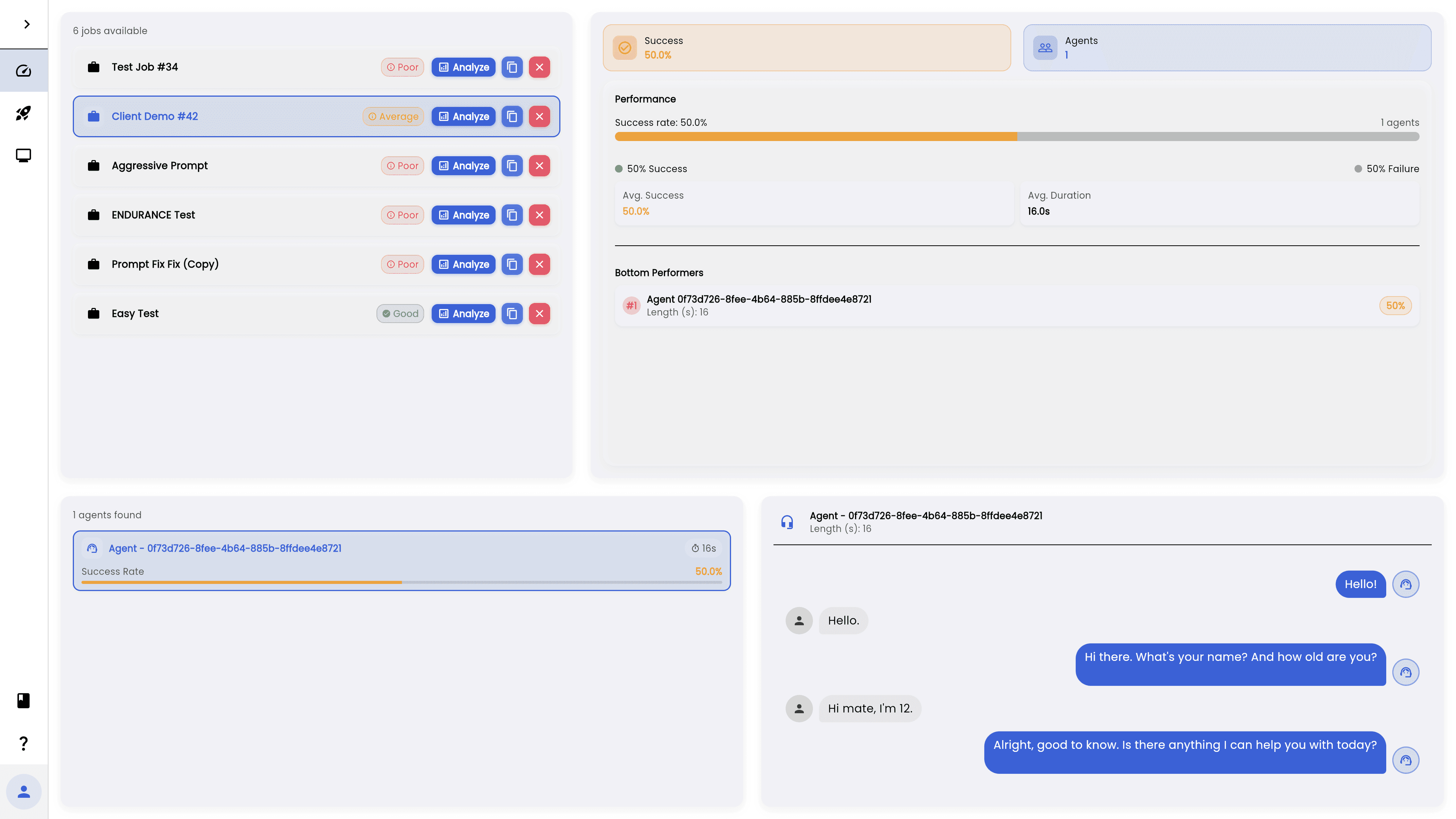
Simulate, debug, and monitor — all in one place
Design experiments, deploy agents, simulate behaviors, and track every insight, all within one controlled testing environment.
Industry Analytics
Reveal hidden failure modes, hallucinations, and blind spots in your AI agents by running realistic, high-pressure conversations before deployment.
Lightning Fast
Run large-scale agent simulations in seconds, giving you instant insight into failures, reasoning breakdowns, and performance bottlenecks before they reach production.
Production Monitoring
Effortlessly monitor agents in production, catch failures, detect drift, and surface anomalies in real time.
Simulate to Expose
Reveal hidden failure modes, hallucinations, and blind spots in your AI agents by running realistic, high-pressure conversations before deployment.
Simulate, debug, and monitor — all in one place
Design experiments, deploy agents, simulate behaviors, and track every insight, all within one controlled testing environment.
Industry Analytics
Reveal hidden failure modes, hallucinations, and blind spots in your AI agents by running realistic, high-pressure conversations before deployment.
Lightning Fast
Run large-scale agent simulations in seconds, giving you instant insight into failures, reasoning breakdowns, and performance bottlenecks before they reach production.
Production Monitoring
Effortlessly monitor agents in production, catch failures, detect drift, and surface anomalies in real time.
Simulate to Expose
Reveal hidden failure modes, hallucinations, and blind spots in your AI agents by running realistic, high-pressure conversations before deployment.
Simulate, debug, and monitor — all in one place
Design experiments, deploy agents, simulate behaviors, and track every insight, all within one controlled testing environment.
Industry Analytics
Reveal hidden failure modes, hallucinations, and blind spots in your AI agents by running realistic, high-pressure conversations before deployment.
Lightning Fast
Run large-scale agent simulations in seconds, giving you instant insight into failures, reasoning breakdowns, and performance bottlenecks before they reach production.
Production Monitoring
Effortlessly monitor agents in production, catch failures, detect drift, and surface anomalies in real time.
Simulate to Expose
Reveal hidden failure modes, hallucinations, and blind spots in your AI agents by running realistic, high-pressure conversations before deployment.
Trusted by
With Critica, we uncovered edge-case failures in our pizza-ordering chatbot we didn’t even know existed. It's like hiring a QA team that never sleeps — and never misses.

Dominos
Restraunt
Critica let us simulate thousands of customer-agent conversations before launch for our clients. We now catch tone issues, hallucinations, and routing problems — all before they affect brand trust.

Nespon
Consulting
Regulatory compliance is critical in finance. Critica gives us full observability into our AI agents’ decision paths — so we can explain, audit, and fix issues with confidence.
Bank in Argentina [redacted]
Finance
Through Critica, we could test our chatbot before we deployed it to thousands of people. We caught errors, before the public could.
[redacted]
[redacted]
With Critica, we uncovered edge-case failures in our pizza-ordering chatbot we didn’t even know existed. It's like hiring a QA team that never sleeps — and never misses.
Dominos
Restraunt
Critica let us simulate thousands of customer-agent conversations before launch for our clients. We now catch tone issues, hallucinations, and routing problems — all before they affect brand trust.
Nespon
Consulting
Regulatory compliance is critical in finance. Critica gives us full observability into our AI agents’ decision paths — so we can explain, audit, and fix issues with confidence.
Bank in Argentina [redacted]
Finance
Through Critica, we could test our chatbot before we deployed it to thousands of people. We caught errors, before the public could.
[redacted]
[redacted]
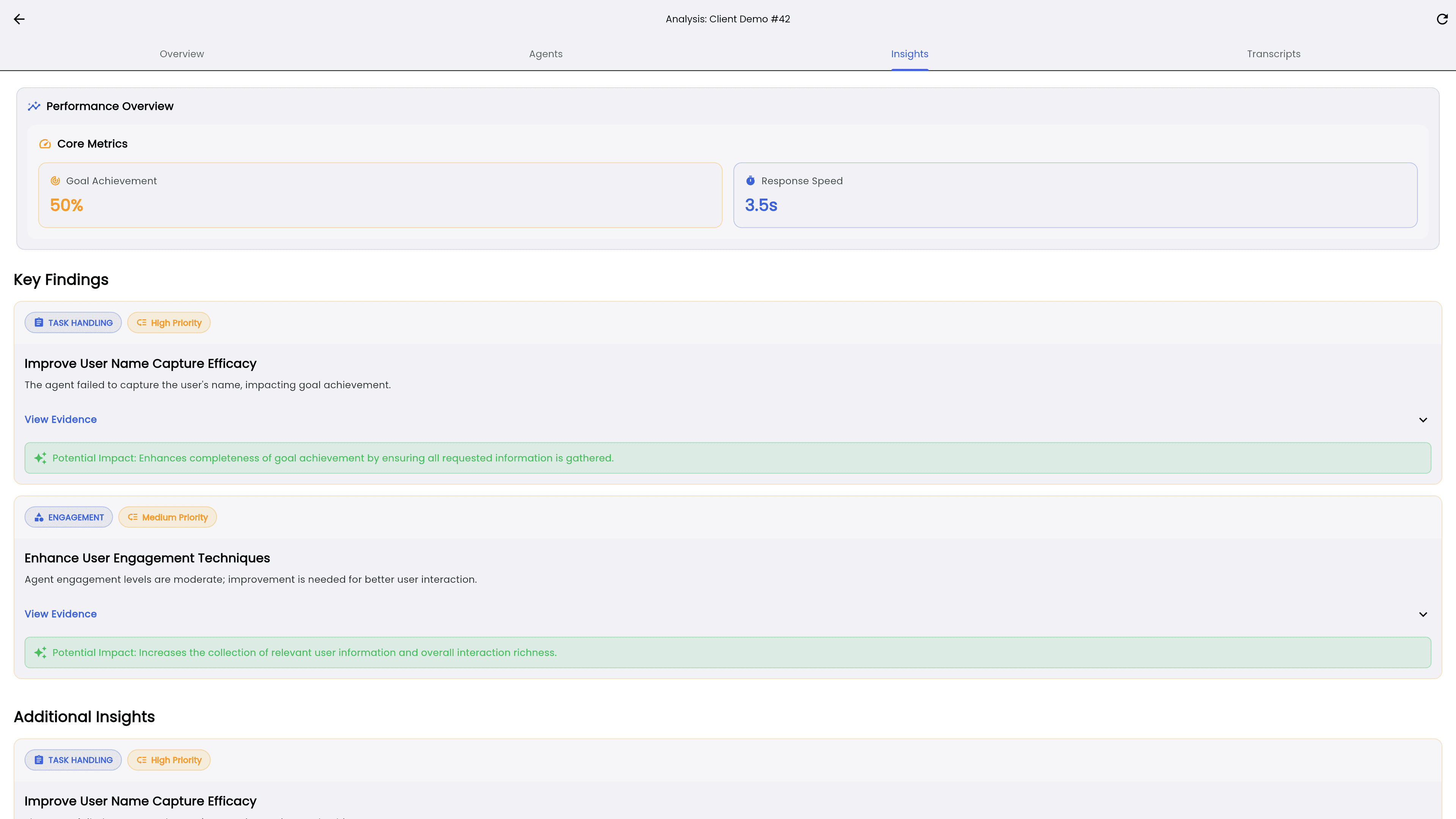
E2E AI Observability, Unified
Take control of your AI agents by capturing and organizing all your simulations, conversations, failures, metrics, reasoning traces, and performance logs in one streamlined system.

Active Monitoring
Easily manage not just simulated conversations but also real production calls with full visibility into agent behavior.

Custom KPIs
Effortlessly track industry-specific agent performance, benchmark behaviors, and uncover failure patterns across domains.

Build Better
Use your failed test cases as starting points to generate targeted simulations that stress-test your agents where it matters most.
E2E AI Observability, Unified
Take control of your AI agents by capturing and organizing all your simulations, conversations, failures, metrics, reasoning traces, and performance logs in one streamlined system.
Active Monitoring
Easily manage not just simulated conversations but also real production calls with full visibility into agent behavior.
Custom KPIs
Effortlessly track industry-specific agent performance, benchmark behaviors, and uncover failure patterns across domains.
Build Better
Use your failed test cases as starting points to generate targeted simulations that stress-test your agents where it matters most.
E2E AI Observability, Unified
Take control of your AI agents by capturing and organizing all your simulations, conversations, failures, metrics, reasoning traces, and performance logs in one streamlined system.
Active Monitoring
Easily manage not just simulated conversations but also real production calls with full visibility into agent behavior.
Custom KPIs
Effortlessly track industry-specific agent performance, benchmark behaviors, and uncover failure patterns across domains.
Build Better
Use your failed test cases as starting points to generate targeted simulations that stress-test your agents where it matters most.
FAQ
Frequently Asked Questions
How does this work?
Critica works by simulating realistic conversations between AI user agents and your support systems. We capture every decision, trace, and outcome to expose failures, hallucinations, and blind spots. These simulations run alongside real production calls, giving you unified observability across test and live environments. With every interaction, your agents get smarter — and your AI becomes more reliable.
What value can I get from this?
Critica helps you catch AI failures before your users ever see them. You gain deep observability into agent reasoning, behavior drift, and performance breakdowns — all in one place. By turning failed conversations into insights, you can continuously improve your models with precision. The result: fewer escalations, smarter agents, and faster iteration cycles.
Do you offer a startup grant?
Yes — Critica offers a startup grant for early-stage teams building with AI support systems. If you're under a certain revenue or funding threshold, you may qualify for free credits and onboarding support. We want to help you test, simulate, and improve your agents without cost being a blocker. Reach out to us, and we’ll review your eligibility within 48 hours (founders@trycritica.com).
How reliable are your evals?
Critica’s evaluations are built to be reliable, consistent, and aligned with real-world performance expectations. Our system automatically flags low-confidence results, which are then reviewed and validated by trained human data labelers for added accuracy. This hybrid approach ensures critical failures and edge cases aren’t missed by automated metrics alone. You get both speed from automation and trust from human-in-the-loop verification.
FAQ
Frequently Asked Questions
How does this work?
Critica works by simulating realistic conversations between AI user agents and your support systems. We capture every decision, trace, and outcome to expose failures, hallucinations, and blind spots. These simulations run alongside real production calls, giving you unified observability across test and live environments. With every interaction, your agents get smarter — and your AI becomes more reliable.
What value can I get from this?
Critica helps you catch AI failures before your users ever see them. You gain deep observability into agent reasoning, behavior drift, and performance breakdowns — all in one place. By turning failed conversations into insights, you can continuously improve your models with precision. The result: fewer escalations, smarter agents, and faster iteration cycles.
Do you offer a startup grant?
Yes — Critica offers a startup grant for early-stage teams building with AI support systems. If you're under a certain revenue or funding threshold, you may qualify for free credits and onboarding support. We want to help you test, simulate, and improve your agents without cost being a blocker. Reach out to us, and we’ll review your eligibility within 48 hours (founders@trycritica.com).
How reliable are your evals?
Critica’s evaluations are built to be reliable, consistent, and aligned with real-world performance expectations. Our system automatically flags low-confidence results, which are then reviewed and validated by trained human data labelers for added accuracy. This hybrid approach ensures critical failures and edge cases aren’t missed by automated metrics alone. You get both speed from automation and trust from human-in-the-loop verification.
FAQ
Frequently Asked Questions
How does this work?
Critica works by simulating realistic conversations between AI user agents and your support systems. We capture every decision, trace, and outcome to expose failures, hallucinations, and blind spots. These simulations run alongside real production calls, giving you unified observability across test and live environments. With every interaction, your agents get smarter — and your AI becomes more reliable.
What value can I get from this?
Critica helps you catch AI failures before your users ever see them. You gain deep observability into agent reasoning, behavior drift, and performance breakdowns — all in one place. By turning failed conversations into insights, you can continuously improve your models with precision. The result: fewer escalations, smarter agents, and faster iteration cycles.
Do you offer a startup grant?
Yes — Critica offers a startup grant for early-stage teams building with AI support systems. If you're under a certain revenue or funding threshold, you may qualify for free credits and onboarding support. We want to help you test, simulate, and improve your agents without cost being a blocker. Reach out to us, and we’ll review your eligibility within 48 hours (founders@trycritica.com).
How reliable are your evals?
Critica’s evaluations are built to be reliable, consistent, and aligned with real-world performance expectations. Our system automatically flags low-confidence results, which are then reviewed and validated by trained human data labelers for added accuracy. This hybrid approach ensures critical failures and edge cases aren’t missed by automated metrics alone. You get both speed from automation and trust from human-in-the-loop verification.
Let's build better AI Agents, together
Schedule a 30-minute demo, to see how Critica can help close your QA pipeline, allowing you to ship better AI.
Let's build better AI Agents, together
Schedule a 30-minute demo, to see how Critica can help close your QA pipeline, allowing you to ship better AI.
Let's build better AI Agents, together
Schedule a 30-minute demo, to see how Critica can help close your QA pipeline, allowing you to ship better AI.
© Copyright 2025 Critica Technologies
© Copyright 2025 Critica Technologies
© Copyright 2025 Critica Technologies